Stop Using Hashes for Detection (and When You Should Use Them)
Fun fact! When I published the Pyramid of Pain in 2013 it didn’t exactly match up with today’s version. Here’s what it originally looked like:

Notice anything different? The bottom level of the Pyramid was originally “IP Addresses”. It wasn’t until almost a year later that I revised it to include a new layer for static hashes (e.g. MD5 or SHA1) as the bottom level.
It’s not that I forgot hashes existed. How could I, when they are a major component of many of our threat intel feeds? The reason I didn’t originally include hashes is because they are terrible for incident detection and using them for that is a waste of time. It was only after I got so many questions about where they fell on the Pyramid that I relented and released a version including them at their rightful place on the bottom.
Why Hashes are Bad for Detection
I teach network forensics for SANS, and as part of that class we use the Pyramid to discuss the types of IOCs that forensics commonly produces. I start at the bottom of the Pyramid and work my way up, so pretty much the first thing I tell my students about IOCs is that hash values received from others (which we’ll call third-party hashes) are not useful for detection. This is because hashes are the most volatile and easiest to change of all the common types of IOCs. Flip one bit, or maybe just recompile a binary and the hash changes.
Interestingly, hashes are by far the highest fidelity of all the common indicator types because they don’t generate false positive matches. If you are looking for a hash and you find a match, it’s pretty much guaranteed that you found exactly what you were looking for. Of course, I’m aware that hash collision attacks exist, but threat actors generally use those to match a known-benign hash value to evade detection, and we probably wouldn’t be looking for benign hash values for incident detection. We can safely discount those.
“Zero false positives” sounds great, right?? Here’s the problem with hashes: if you get a hot tip about a malicious hash from an intel feed or vendor report, you’re extremely unlikely to ever find a file matching that hash in your own environment. Hashes are just too easily and frequently changed to be effective as IOCs. The unfavorable effort/reward ratio means it’s too expensive for the tiny amount of value you get out of it.
I formed this conclusion based on personal experience running a detection program for a huge multinational company and my opinion hasn’t changed since then. However, it recently occurred to me that “personal experience” isn’t measurable and therefore may not be the best data upon which to base such a conclusion. I realized, though, that there might be a way to measure the detection effectiveness of hash values more objectively.
Hypothesis
Data
- The item had an MD5 hash value. This returns only files and not URLs that might also have been submitted for scanning. I used the unique MD5 values to identify all the different files.
- At least five different AV products marked it as malicious. This threshold is arbitrary, but I wanted to find only files that were probably malicious and guard against false positives from a single AV vendor.
- The file was submitted anytime during 2021. Technically, the time range was January 1st 2021 00:00:00 UTC or after, but before January 1st 2022 00:00:00 UTC. Analyzing an entire year’s worth of data ensures our sample size is large enough to allow us to draw accurate conclusions.
- The file had to have at least one submitter. This sounds odd, but there were a very small number of files (~1,200) that were somehow marked as having zero submitters. This is nonsense since someone had to submit these files for them to appear in the database. I removed these from the dataset.
Assumptions
- There is a one-to-one mapping between submitters and organizations. This may not be true in all cases, as it may be possible for a single organization to have multiple submitter IDs. In general, we expect this assumption to hold. VirusTotal allocates submitter IDs for each unique account, which are usually tied to individuals. However, most organizations who submit files regularly do so via automated processes, which typically run from a single account, and thus a single submitter ID. We expect that there will be a significant number of manual submissions, but that the sheer number of automated submissions will drown these out.
- The number of submitters is a good proxy for the number of organizations that observed the file. This is the assumption upon which the validity of the conclusions will rest, but it is a safe assumption. Since we’re dealing with malware, there’s a very good chance that some organizations will not detect the file’s presence on their network but given the very large number of submitters that routinely send files to this service, the chances of malware evading detection at nearly all sites for an entire year is small enough to discount their effect on the analysis.
Analysis
# of Submitters Count of Files Percent of Total Files
1 10390005 91.81
2 649727 5.74
3 115159 1.02
4 47839 0.42
5 27759 0.25
6 15735 0.14
7 12243 0.11
8 8506 0.08
9 6833 0.06
10 5798 0.05
> 10 37153 0.33
If you prefer to see this visually, here’s what the histogram looks like:
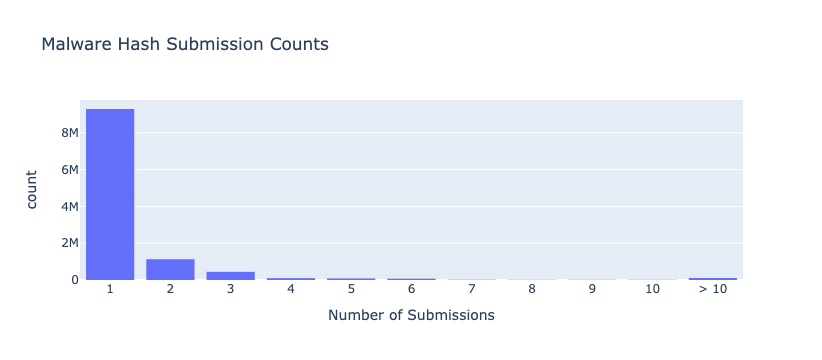
As you can see, most malicious files (91.81%) were submitted from only a single source. There were also a substantial number of files submitted by exactly two (5.74%) or three (1.02%) sources. Together those three categories account for 98.57% percent of all malicious files. All the other categories were well below 1% of files (“4 submitters” was at 0.42% and they fell sharply from there).
Even lumping the remaining values into a “more than 10 submitters” category accounted for only 0.33% of all files. If we expect to detect third-party hash values on our own networks, we’d need to see many more files fall into this category. There’s no specific threshold for what this number should be for third-party hashes to be useful for detection, but 0.33% is well under any reasonable effectiveness threshold.
When Hashes Might be Useful for Detection
Conclusion
Article Link: Enterprise Detection & Response: Stop Using Hashes for Detection (and When You Should Use Them)
1 post - 1 participant
